RAG系统理论学习
RAG系统理论学习
对于RAG应用的检索系统搭建的理论与工程部分进行学习。
参考文献:https://arxiv.org/abs/2312.10997
0 引入
当LLM遇到超出其训练数据或遇到需要查询当前数据时,就会产生hallucinations幻觉现象。现在通过RAG技术,在外部知识库中通过计算语义相似度semantic similarity calculation,检索相关文档块,降低幻觉产生。
阶段特征
- 与Transformer架构的融合:通过预训练模型与额外知识的合并,增强语言模型。这个阶段的目的是细化预训练技术。
- 与LLM架构的融合:ChatGPT的出现展现了LLM的强大ICL能力。此时,RAG技术转向为LLM在推理阶段的信息提供。如今开始偏向结合LLM的微调技术。
1 RAG的主要概念和当前范式
RAG最典型的应用是与ChatGPT结合,补充ChatGPT在训练时与当前世界的信息差距,将外部数据中搜索到的信息+用户提问形成一个全面的Prompt,促使LLM生成更好的答案。
1.1 RAG技术的3个阶段
1. Naive RAG
RAG技术的早期阶段,高光时刻是在ChatGPT被广泛采用的时候。这个时候的框架称作Retrieve-Read框架,包括了索引、检索和生成。
整体流程:
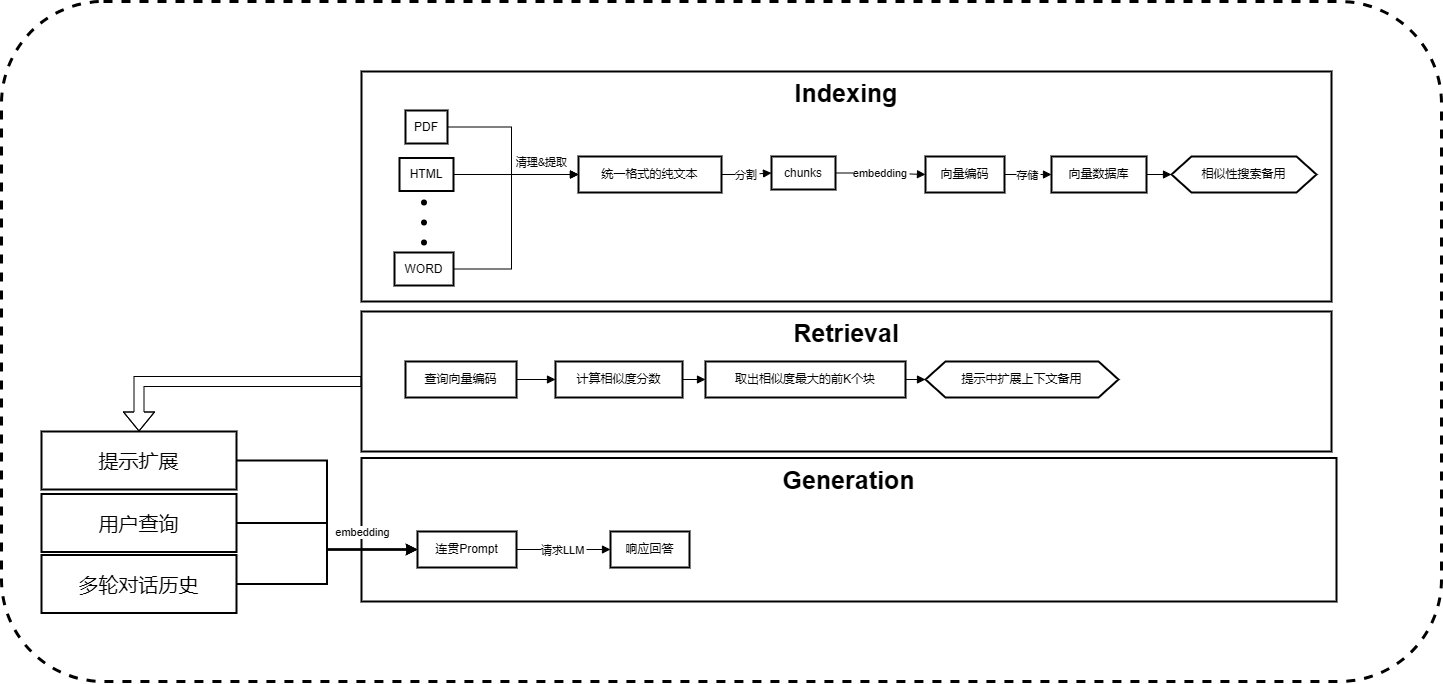
缺陷:
- 检索:精度和召回率比较捉急,会发生
选择错块、选择不相关的块、关键信息缺失等问题。 - 生成:幻觉问题,也存在不相关性、毒性、偏差等问题。
- 增强障碍:检索信息与不同任务结合的挑战。会出现不相交性或不连贯性。当出现相似信息检索时会出现冗余处理。面对复杂问题,基于原始查询的单个检索可能不足以获得足够的上下文信息。
- LLM过于依赖检索信息,以至于输出仅是检索内容的简单回声,无法获得需要洞察力的或者合成的信息。
2. Advanced RAG
Advanced RAG是在Naive RAG上进行改进,它专注于提高检索质量,采用预检索和后检索策略。索引技术使用滑动窗口、细粒度分割和元数据结合的方法。还结合了其他几种优化策略使得检索过程更加流水线。
- 预检索过程:优化索引结构和原始查询。
- 优化索引结构:提高被索引内容的质量
- 增强数据粒度
- 优化索引结构
- 增加元数据
- 对齐优化
- 混合检索
- 优化索引结构:提高被索引内容的质量
3. Modular RAG
2 核心组成——检索、生成和增强
3 检索优化——索引、查询和嵌入优化。
4 三个增强过程
5 RAG 的下游任务和评估系统
6 不足之处
RAG系统理论学习
https://yui73.github.io/2024/07/15/RAGLearning/